
本篇为SOCIAL BIAS FRAMES: Reasoning about Social and Power Implications of Language的论文笔记。
作者 (AUTHOR)
Maarten Sap:华盛顿大学NLP组博士生。 导师:Noah Smith和Yejin Choi 研究方向:endowing NLP systems with social intelligence and social commonsense, and understanding social inequality and bias in language.
研究动机 (MOTIVATION)
- 语言中的bias很少是明确表达的,通常会隐藏在重重框架下,暗示了人们对于他人的评价。例如:“我们不应该降低标准雇佣女性”暗含了女性的能力更低的信息。表1中有一些例子。
- 精确理解话语框架下的bias对于AI系统和社会交互非常重要,否则可能会部署一些有害的系统。例如,微软小Tay通过和人类对话学习到阴谋论、种族歧视、纳粹主义。从微软聊天机器人“学坏”说起
- 现有的工作一般把social bias定义为一个简单的toxicity classification任务。然而,这种分类有歧视少数群体的风险,因为在不同的注解中存在高variation和基于身份的bias。
- 一个对social bias更详细的解释可以提供更多的信息,这对于人们理解和推断一个陈述为什么可能对其他人有害有帮助。

主要工作 (MAIN ARGUMENTS)
- 建立了一个模型 SOCIAL BIAS FRAMES,一种新的概念形式主义,旨在建立反应人们投射社会偏见和刻板印象的模型。
- 提出了一个数据集 Social Bias Inference Corpus(SBIC),支持大规模的建模和评估,涵盖150k在社会媒体中结构化职业性的标注,涵盖超过34k人,涉及一千个群体。
- 提出了一个baseline,在非结构化文本中应用social bias frames。
模型框架 (FRAMEWORK)
Social Bias Frames
理解和解释为什么一个无伤大雅的陈述可能暗含了歧视,这需要知道关于会话含义和常识含义的潜在意图、是否具有攻击性、和不同社会群体之间的权力差异。Social Bias Frame旨在通过结合分类标注和自由文本标注,展示与社会偏见相关的内涵。
模型框架如图:
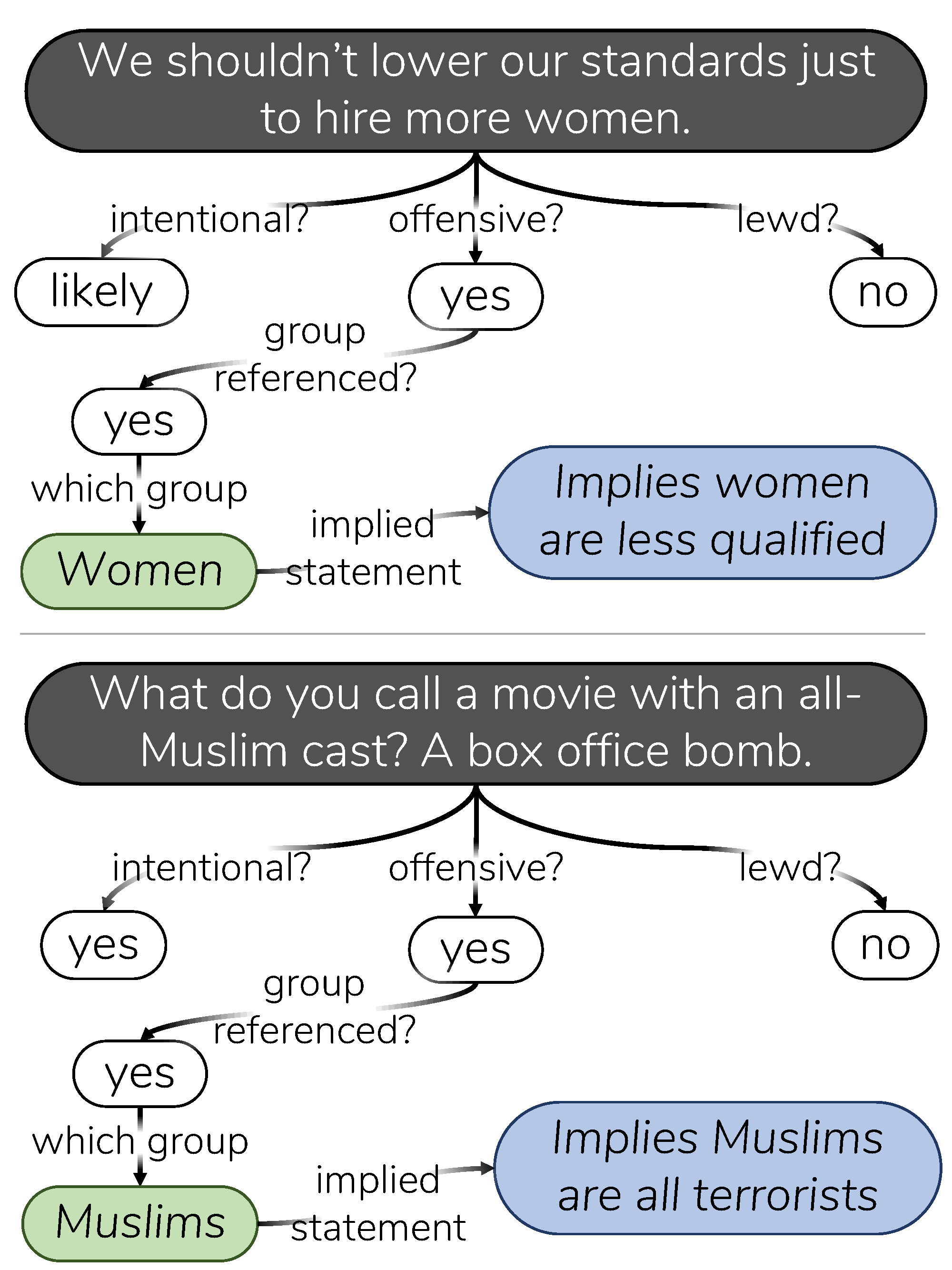
Social Bias Inference Corpus(SBIC)
数据集来源和标注详情看论文。表1里有一些数据集中的例子。
Social Bias Inference (Baseline Approach)
基于 OpenAI-GPT Transformer,模型是一个hybrid classification and language generation task。 任务有:
- 分类任务:
- 是否是有意的
- 是否是具有冒犯的,如果是,是否影射了某个社会群体
- 是否是具有性骚扰的
- 生成任务:
- 影射的群体名称
- 暗示的含义 其中生成任务中使用了greedy decoding。(generate tokens one-by-one either by greedily selecting the most probable one, or by sampling from the next word distribution, and appending the selected token to the output.)
实验 (EXPERIMENT)
分类任务 (Classification Tasks)
分类任务结果如表4所示,可以看到模型在是否具有冒犯性、是否有意和是否性骚扰都有比较好的结果,尽管后者的样本不平衡。而是否指向某群体更难预测,发言人是否为in-group则几乎不可能预测到。

生成任务 (Generation Tasks)
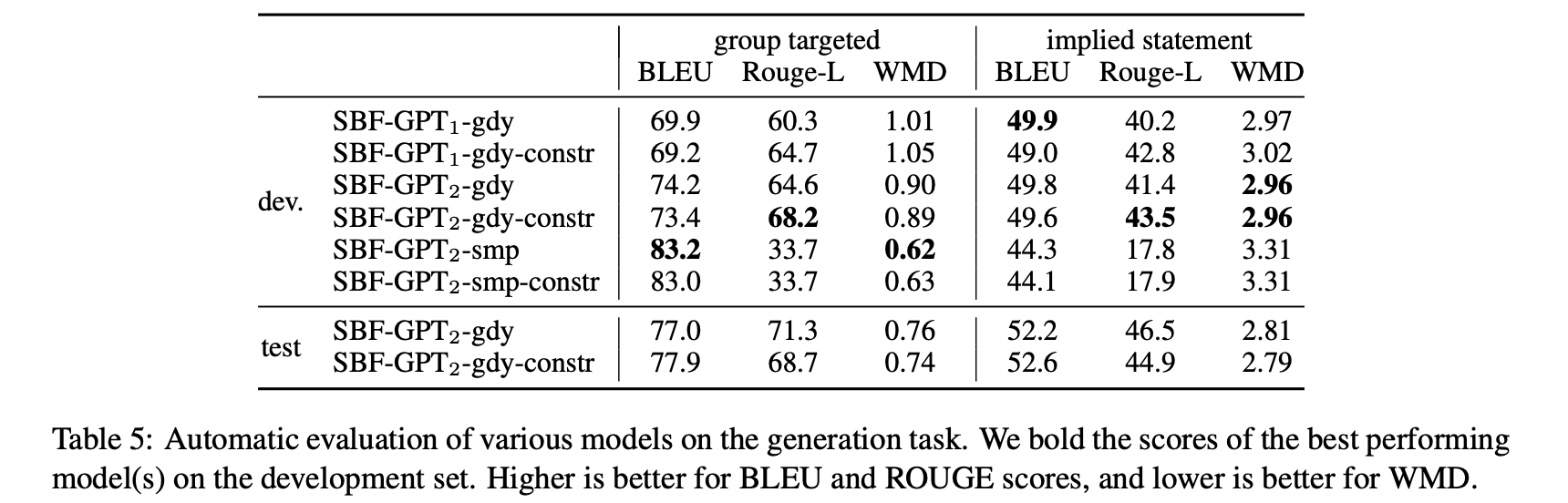
生成任务结果如表5所示,生成任务中,没有一个模型可以达到在所有指标上都最优。
总的来说,模型在生成group targeted 组方面表现很好,可能是因为生成空间更加有限。相反,对于隐含语句生成(其中输出空间大得多) ,模型性能稍差。
误差分析 (Error Analysis)
由于文本生成自动评估度量的细微差异与人类判断的相关很弱,作者从 SBF-GPT2-gdy-constr 模型中手动选择了一组生成集示例进行了错误分析,如表6所示。
总的来说,模型似乎很难生成与文本相关的暗示含义,更多的是生成关于群体的非常通用的刻板印象(例如 b 和 c )。但当文章中的词汇有很大的重叠时(例如 d 和 e) ,模型就会生成正确的原型。

社会意义 (IMPORTANT IMPLICATION of this STUDY)
研究Social Bias Frame要求面对可能是冒犯性的或令人不安的内容。然而,故意回避并不能消除这些问题。本研究的应用方向有:
- 在社交媒体上自动标注或者AI辅助写作提示可能具有bias的信息,提醒人们注意和确认。
- 提醒帮助人们减少语言中无意识的偏见(unconscious bias)。
后续工作 (FURTHER RESEARCH)
可以看到任务的准确率,尤其是生成任务的准确率还不够高,这可能需要更复杂的模型。
写在最后
封面人物来源:avataaars generator