
本文为论文 What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context 的论文笔记。该论文为2020年发表在ACL上的长文。
报告PPT链接开放下载:What Was Written vs. Who Read It.pdf
介绍
作者 (AUTHOR)
Ramy Baly
Senior Scientist at Accrete American University of Beirut (AUB) PhD. Research Field: machine learning, NLP (text categorization, sentiment analysis, machine translation evaluation, fake news detection, media source reliability prediction)
Georgi Karadzhov
PhD at University of Cambridge, supervised by Andreas Vlachos. Reasearch Field: applied machine learning and natural language processing research (fact-checking and dialogue systems) personal home: https://gkaradzhov.com/
背景 (MOTIVATION)
- 互联网的崛起让每个人都可以创立网站和博客,成为新闻媒体。
- 而社交媒体让每个人的声音都可以被听到。
- 这就带来了一定的危机,也就是fake news。有数据显示,fake news在推特上的传播速度几乎是真实新闻的六倍[1]。而50%的fake news快速传播都发生在十分钟内 [2]。
工作 (CONTRIBUTION)
本篇文章的工作主要有:
- 对媒体的政治倾向(左、中、右)和报道可信程度(高、一般、低)做推断
- 对于每个媒体使用了多个角度(多模态)进行建模学习:(i) what they publish. (ii) who reads it. (iii) what was written about the target medium on Wikipedia
- 将目标媒体的一系列信息进行组合,使用了多模态提取特征,包括了: text, metadata, and speech,而非传统的text。
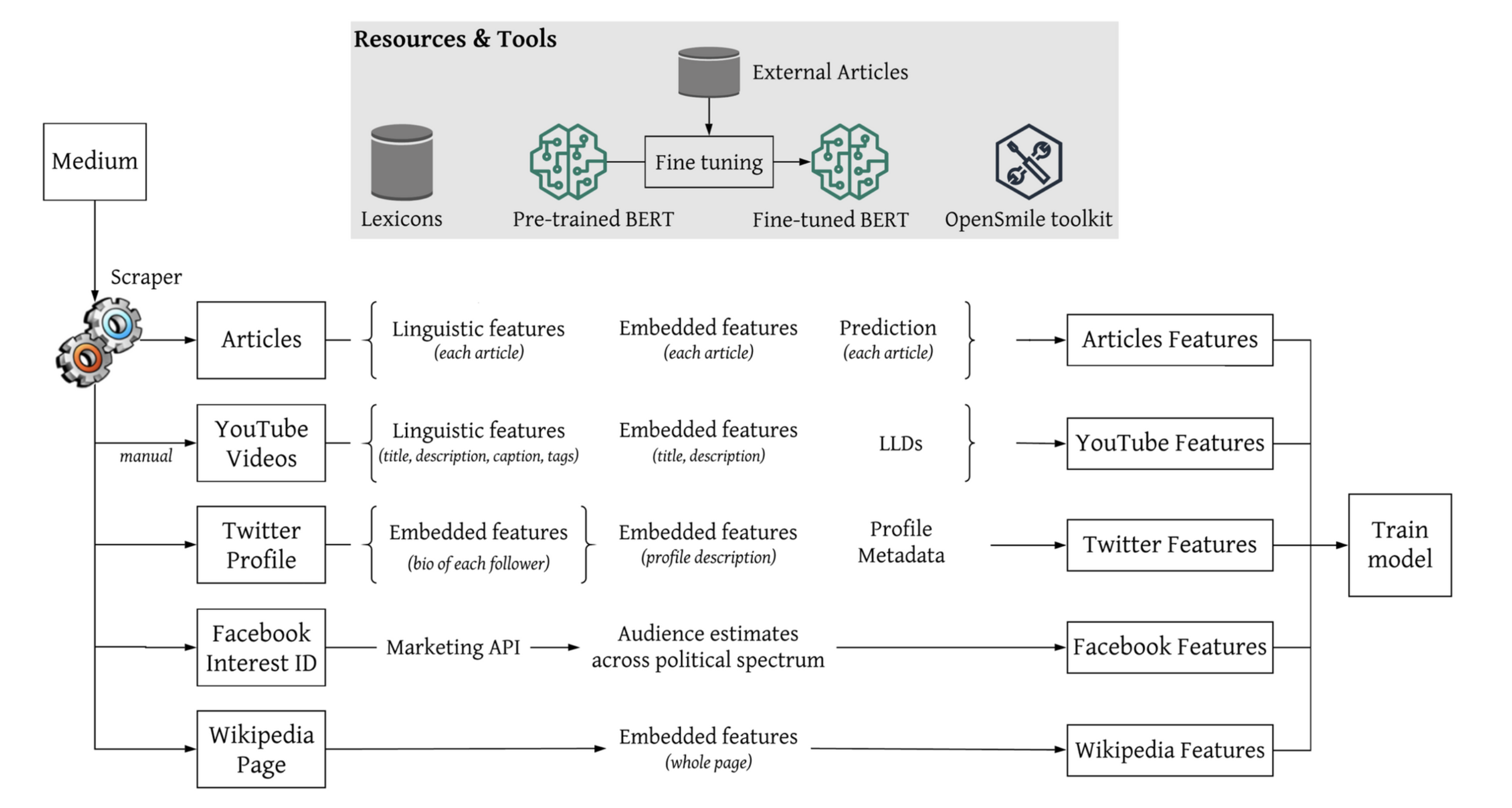
框架 (FRAMEWORK)
对于每个目标的媒体,提取三个方面的特征:
- 媒体中发表的信息
- Articles on the News Medium Website
- YouTube Video Channel
- Media Profiles in Twitter
- 社交媒体上媒体的受众群体
- Twitter Followers Bio
- Facebook Audience
- YouTube Audience Statistics
- 媒体的维基百科页
利用这些特征,使用支持向量机分类器进行训练,用于预测新闻媒体报道的政治倾向和真实性。
What was Written
媒体发布的信息很大程度上决定了他们的政治倾向和可信程度。
- Articles on the News Medium Website
作者从媒体的网站中爬取了一系列新闻文章,然后在文章中提取特征。
- Linguistic Features:使用 News Landscape (NELA) toolkit[3] 在文章中抽取了 NELA features,包括了 text structure, topic, sentiment, subjectivity, complexity, bias, and morality。
- Embedded Features:使用BERT训练得到Word Representations,标签对媒体打的标签。
- Prediction:使用BERT中[CLS] token 输出到一个softmax layer,对每个标签做出预测的概率。
- YouTube Video Channel
作者在YouTube频道中选择了25个音频时间大于15s的视频,然后将每个音频切割称15秒/节。对每节做特征提取。
- Linguistic Features:使用 News Landscape (NELA) toolkit 对视频中的附加文本中的抽取了 NELA features,包括了 text structure, topic, sentiment, subjectivity, complexity, bias, and morality。
- Embedded Features:使用BERT对视频的描述,标题,标签,主题进行训练做encoding。
- LLDs:使用OpenSMILE toolkit[5] 对音频提取low-level descriptors (LLDs),包括frame-based features (e.g., energy), fundamental frequency, and Mel-frequency cepstral coefficients (MFFC)。这些特征在情感检测上被证明是有效的。[4]
- Media Profiles in Twitter 作者爬取了媒体的Twitter账号信息,包括:是否对账户进行了验证、创建年份、地理位置,还有其他一些统计数据,例如关注者数量和发布推文数量。 使用 SBERT 对这些信息的描述做encoding,使用SBERT原因有: (i)Twitter账号信息的数量太少,对 BERT 做fine-tune不合适; (ii)大多数 Twitter 的账号信息具有句子的结构和长度大小
Who Read it
假定 (i)受众可能会和媒体的政治倾向一致,(ii) 他们可能会在自我简介中表达自己的政治倾向。
- Twitter Followers Bio 对每个媒体的推特账号选取5000个关注者,过滤掉非英文文本,然后使用SBET对每个follower的简介做encoding
- Facebook Audience Facebook提供了一个广告接口(interesting ID),通过ID,可以找到对该媒体感兴趣的用户。然后对用户进行政治光谱对评估。
- YouTube Audience Statistics 检索了以下metadata: 每个视频的观看次数、喜欢量、不喜欢量和评论量。
What Was Written About the Target Medium
维基百科的内容中通常会对媒体的政治倾向和可信程度做说明。文中使用BERT对媒体对维基百科页做encoding。
实验 (EXPRIMENT)
Dataset
同一作者在2018年发布的数据集:Media Bias/Fact Check。这个数据来自 Media Bias/Fact Check (MBFC) website ,包含了手动标注的超过2000个媒体的可靠程度和政治倾向。
dataset and the code: http://github.mit.edu/CSAIL-SLS/News-Media-Reliability/
Baseline
- majority class baseline
- 作者以前的工作 [6]
- 媒体文章的 NELA features
- 维基百科页面的GloVe word embeddings
- 媒体推特信息的元数据
- URL结构化的feature
Strategy
- Concatenate Features
- Ensemble Modeling
Result
Political Bias Prediction
从表中可以看出,当三部分最好的features项做集成学习时,得到的结果最好。 What They Publish > Who Read It
Factuality of Reporting
当 What was written 和 What was written about the target medium 中的特征项拼接做学习时,效果最好。 受众的特征反而对结果产生了负面的影响。 What was written > Who Read It
后续工作 (FURTHER RESEARCH)
- 将其他的模型结构应用到该任务中,例如Graph Embeddings
- 检测媒体的立场或者宣传工具等特征
- 对其他语言做实验
参考文献 (REFERENCE)
[1] Soroush Vosoughi, Deb Roy, and Sinan Aral. 2018. The spread of true and false news online. Science, 359(6380):1146–1151.
[2] Tauhid Zaman, Emily B. Fox, and Eric T. Bradlow. 2014. A bayesian approach for predicting the popularity of tweets. Ann. Appl. Stat., 8(3):1583–1611.
[3] Benjamin D. Horne, Sara Khedr, and Sibel Adali. 2018b. Sampling the news producers: A large news and feature data set for the study of the complex media landscape. In Proceedings of the Twelfth International Conference on Web and Social Media, ICWSM ’18, pages 518–527, Stanford, CA, USA.
[4] Bjo ̈rn Schuller, Stefan Steidl, and Anton Batliner. 2009. The INTERSPEECH 2009 emotion challenge. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, INTERSPEECH ’09, pages 312–315, Brighton, UK.
[5] Florian Eyben, Martin Wo ̈llmer, and Bjo ̈rn Schuller. 2010. openSMILE – the Munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multi-media, pages 1459–1462, Florence, Italy.
[6] Ramy Baly, Georgi Karadzhov, Dimitar Alexandrov, James Glass, and Preslav Nakov. 2018a. Predicting factuality of reporting and bias of news media sources. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP ’18, pages 3528–3539, Brussels, Belgium.
写在最后
封面:
- icon:3d Icons - Iconshock
- 背景:haikei (os: 最近真的爱死haikei了)