
When we say algorithm fairness, what we’re talking about?
当我们在提及算法公平性的时候,我们在谈论什么?
来源:Safety, Bias, and Fairness (guest lecture by Margaret Mitchell) [slides] [video] Stanford / Winter 2019, CS224n: Natural Language Processing with Deep Learning
AI中的bias其实是相当多且广泛的,最普遍的是一个机器翻译的例子:

这是一个土耳其语与英语互译的例子,机器会把原本是无性别的代词翻译为具有性别的代词。
最近在重新看CS224n,课程也正好邀请到了Google AI的研究学者Margaret Mitchell作关于Bias in AI的报告。这里也就将报告的大致内容梳理一下。
Bias in Daily Life
我们日常生活中就无时无刻充斥着偏见。接下来有几个例子说明。
1. 香蕉是什么? 🍌?
这张图片上有什么?What do you see in this picture?

你可能会说 …
- 香蕉
- 标签
- 摆在商店里的香蕉
- 放在货架上的香蕉
- 很多捆香蕉
- 贴上标签的香蕉
- 贴着标签的很多捆香蕉摆在商店里的货架上
- …
但很少会有人说:
这是“黄色的”香蕉
但当看见下面这两张图,我们会说这是“绿色的“香蕉、“成熟的”香蕉、“有斑点的”香蕉。

这是因为,在我们的意识里,“黄色”是香蕉是一种原型特征 (prototypical),是一种基模和常识。
什么是Prototype?
* Prototype Theory:One purpose of categorization is to **reduce the infinite differences** among stimuli **to** behaviourally and **cognitively usable proportions** * There may be some central, prototypical notions of items that arise from stored typical properties for an object category (Rosch, 1975) * May also store exemplars (Wu & Barsalou, 2009)
2. A Simple Cognitive Test…
下面是一个简单的认知测试:
小明的父亲开着一家杂货店。一天,小明从父亲的杂货店出来后被一辆迎面开来的车撞倒。他被送到了医院的急诊室。在手术台上,外科医生忽然发现,手术台上躺的竟是自己的儿子。请问小明与外科医生之间是什么关系?
这是几种可能的回答:
1. 父子关系(he has two dads) 2. 母子关系(he has a mother who's a doctor)
如果你不能迅速而准确地回答上面的问题,恐怕就是基模影响了认知判断过程。你需要仔细审视一下自己的思维过程:很可能问题出在你根据“常识”,做了一个虚假的前提假设一一外科医生都是男性。

事实上,大部分的测试者都忽略了医生是女性的可能性——包括男人、女人,甚至一些自认为是女性主义者的人。
The majority of test subjects overlooked the possibility that the doctor is a she - including men, women, and self-described feminists.
—— Wapman & Belle, Boston University
3. Word Learning from Text
我们谈论事物时就会不自觉地做出假设,它并不一定带有负面的意图,但这在一定程度上说明了事物的概念是如何在我们头脑中储存表示的,也反映了我们在世界上互动时是如何获得这些概念表示的。
这也会影响我们在文本中训练的结果。
这是一份2013年的工作[1]:
| Word | Frequency in corpus |
|---|---|
| “spoke” | 11,577,917 |
| “laughed” | 3,904,519 |
| “murdered” | 2,834,529 |
| “inhaled” | 984,613 |
| “breathed” | 725,034 |
| “hugged” | 610,040 |
| “blinked” | 390,692 |
| “exhale” | 168,985 |
可以发现“murdered”(谋杀)的频率远大于“breathed”(呼吸)和“blinked”(眨眼睛)的频率。但在日常生活中,后两者的发生的频率会远高于前者。人们总是倾向于忽略一些生活中不言而喻的事情。
根据神经网络的特性,输出“murdered”的概率会远超于后两个词。
这种现象被称为Human Reporting Bias。
The frequency with which people write about actions, outcomes, or properties is not a reflection of real-world frequencies or the degree to which a property is characteristic of a class of individuals.
人类关于行为、结果或属性的输出频率并不是真实世界频率的反映,也并不一定是一类事物的真实特征。
这种偏见,其实起源于我们的认知。
BIAS = BAD ??
这里必须要澄清的是,偏见并不一定是一件坏事情。
如果要考虑所有情况的排列组合,我们的大脑可能已经爆炸🤯🤯🤯了。有时候正因为我们拥有着一部分偏见,我们才可以应对这世上各式各样不同的事物,能够把它们变换为可以在现实生活中操作时可控制的东西。
It’s a trick our minds play on us in order to help us process the world.
所以,偏见其实是有好有坏的。
“Bias” can be Good, Bad, Neutral
Bias in Training AI
我们的训练过程,就充斥着偏见(Bias)
首先让我们回忆一下AI的训练过程:
- 收集和标注训练数据
- 训练模型
- 筛选、排序、聚合或生成结果
- 输出
这其中的每一个步骤都充满着人类偏见:
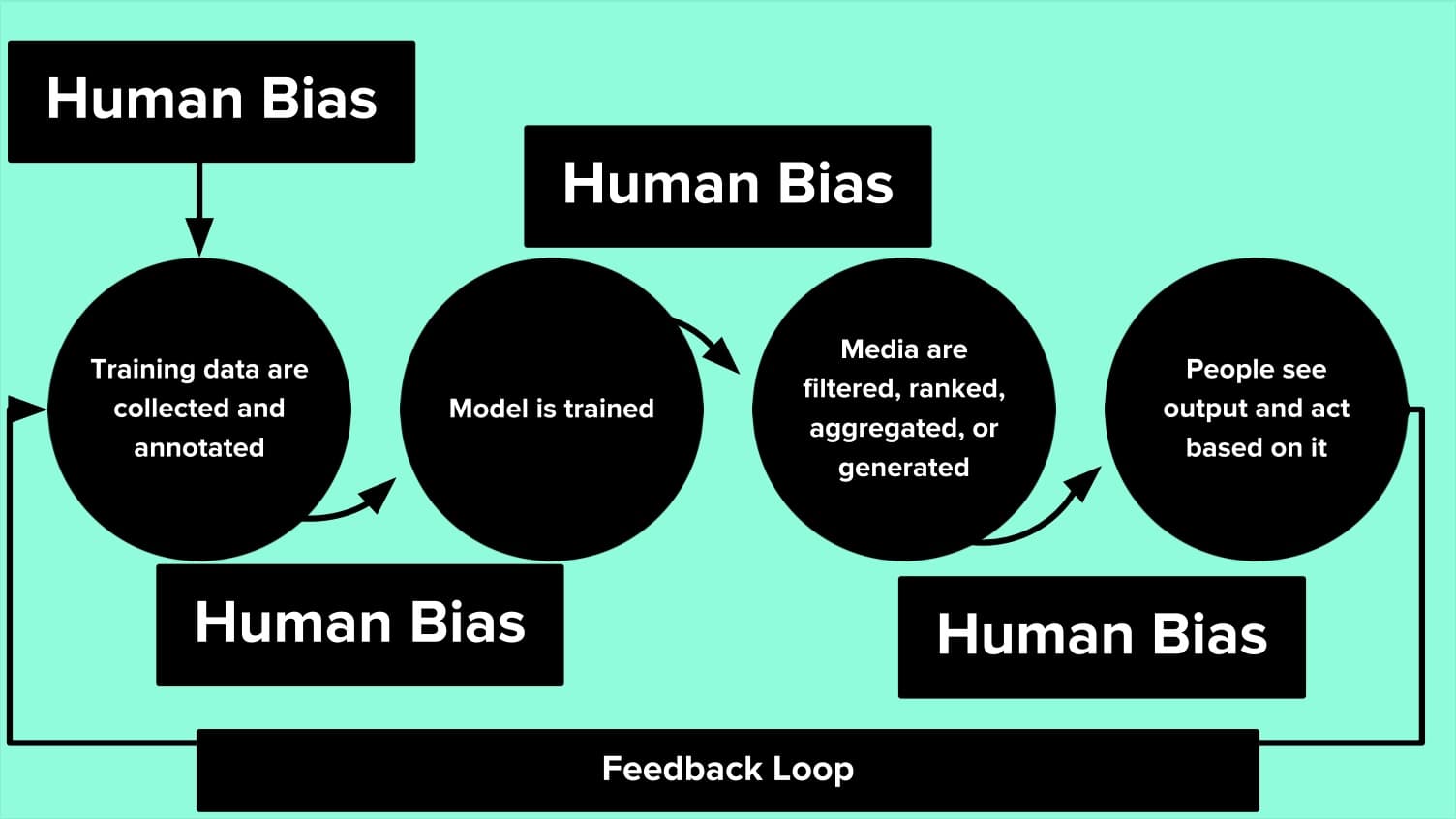
而偏见还会形成反馈循环。这被称为 Bias Network Effect 或者 Bias “Laundering”。
Bias in Data
人类数据延续了人类的偏见。当ML从人类数据中学习时,结果是一个偏置网络效应。
常见的偏见有:
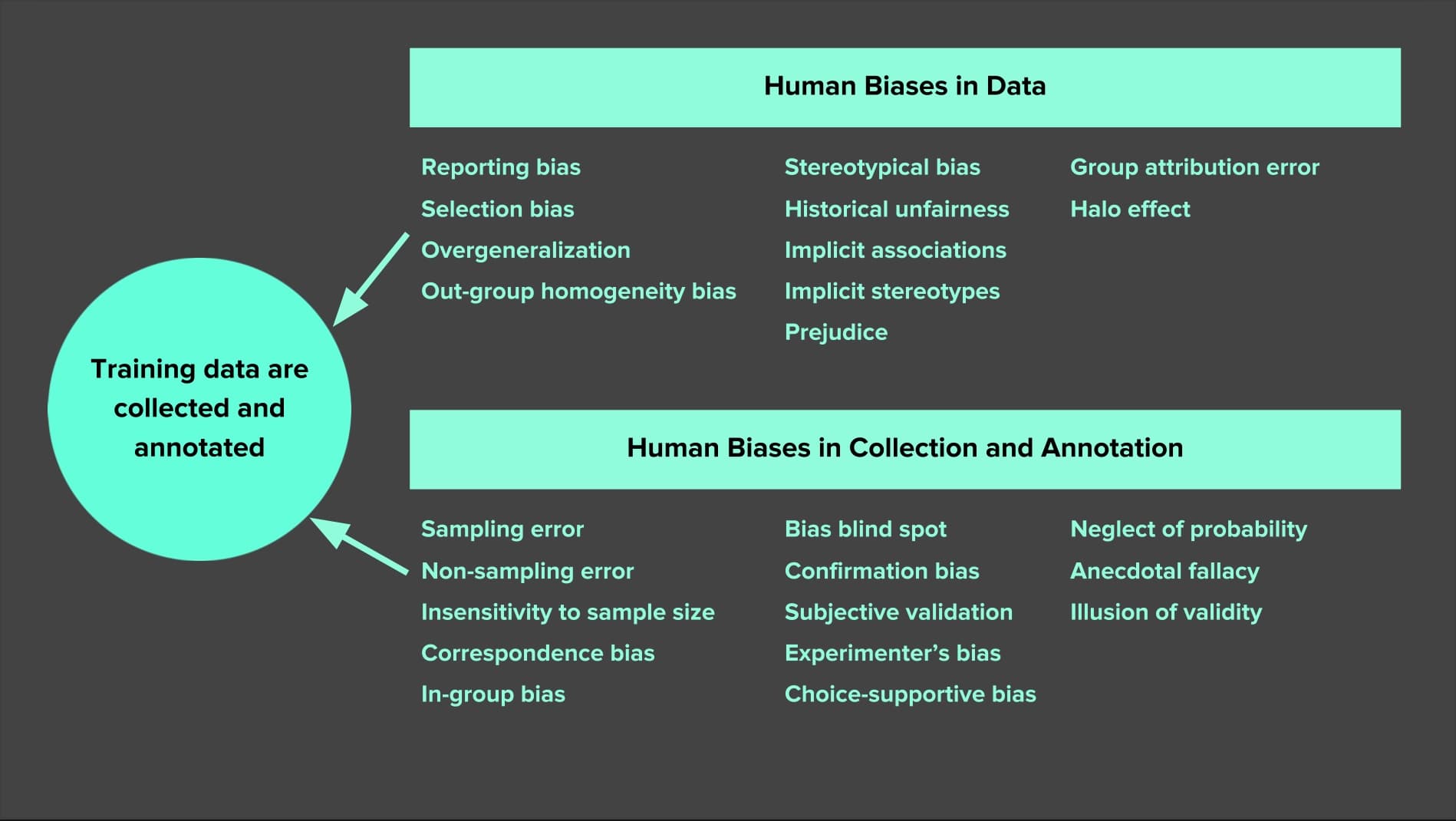
more in : https://developers.google.com/machine-learning/glossary/
- Reporting bias (报告偏见):人们报告的并不是真实世界频率的反映
- Selection Bias (选择偏差):人们的选择并不总是随机样本
- Out-group homogeneity bias (外群体同质性偏见):在比较态度、价值观、性格特征和其他特征时,人们倾向于认为外群体(outgroup)成员比内群体成员(ingroup)更相似。
Bias in Data导致的结果有:
- 具有偏差的数据表示 (Biased Data Representation)
- 具有偏差的标签 (Biased Labels)
Bias in Interpretation
- Confirmation bias (确认偏见):人们倾向于寻找、解释、支持和回忆信息,以确认先前存在的信念或假设
- Overgeneralization (过度泛化):根据过于笼统和/或不够具体的信息得出结论(也与过拟合有关)
- Correlation fallacy (相关性谬误):混淆相关性和因果关系
- Automation bias (自动化偏差):人们更倾向于来自自动化决策系统的建议
Bias in AI
在AI中遇到的偏见大致可以分为这几类:
- 在统计和机器学习中的偏差 (Bias in statistics and ML)
- 估计值的偏差:预测值与我们试图预测的正确值之间的差异
- “偏差”一词 b (如y = mx + b)
- 认知偏见 (Cognitive biases)
- Confirmation bias, Recency bias, Optimism bias
- 算法中的偏见 (Algorithmic bias)
- 对与种族、收入、性取向、宗教、性别和其他历史上与歧视和边缘化相关的特征相关的人的不公平、不公平或偏见待遇,会在算法系统或算法辅助决策中体现出来。
第一种的偏差是客观的可控制的,而第二种偏见来源于我们的现实生活,算法无法改变它。 第三种偏见是需要我们注意和避免的。AI为人类服务,当AI的输入来源于人类提供的偏见数据(即使是无意的),计算机总是会放大这种偏见的想法。
Although neural networks might be said to write their own programs, they do so towards goals set by humans, using data collected for human purposes. If the data is skewed, even by accident, the computers will amplify injustice.
Why Cannot We Amplify Injustice?
为什么说放大偏见是一件不好的事情?接下来有几个算法中放大偏见的例子。
第一个例子是预测性警务 (Predicting Policing)。
算法会预测潜在的犯罪热点区域,可以帮助决策是否要在该区域增加军官部署。这种算法根据以前报告的逮捕地点(注意:并不是发生犯罪的地点)作为训练数据,从过去预测未来可能发生的犯罪地点。 但有一些可能是犯罪的区域可能从来没有被探索到,这部分的可能性为0。而经过数据的循环反复训练,这使得情况会更加恶化。[2]
另一个例子是量刑辅助系统 (Predicting Sentencing)。
经过训练,系统会默认认为黑人的犯罪风险高于白人。经过Automation Bias,过度泛化、循环反馈和相关性谬误,一些错误的例子反复发生,最后形成了某种因果关系。[3]
这样的例子数不胜数:
- Faception是是一家基于人的面部揭示其个性的公司。他们声称可以提供专业的引擎从脸的形象识别“高智商”、“白领犯罪”、“恋童癖”,和“恐怖分子”。其主要客户为国土安全和公共安全。
- 但Google AI 的工作表明,即使是嘴角向上或向下扬起的角度也会影响其判断。[4] (See longer piece on Medium, “Physiognomy’s New Clothes”)

- 这个例子中的偏见有:Selection Bias + Experimenter’s Bias + Confirmation Bias + Correlation Fallacy + Feedback Loops
- 但Google AI 的工作表明,即使是嘴角向上或向下扬起的角度也会影响其判断。[4] (See longer piece on Medium, “Physiognomy’s New Clothes”)
- 某工作声称他们发明了性取向探测器,他们通过从约会网站下爬取下来的35,326张照片预测同性恋者。[5]
“Consistent with the prenatal hormone theory [PHT] of sexual orientation, gay men and women tended to have gender-atypical facial morphology.”

- 但事实上,在自拍中,同性恋和异性恋之间的差异与打扮、表现和生活方式有关,也就是说,这是一种文化的差异,而不是面部结构的差异。甚至可以通过构造一颗简单的打扮特征的决策树来判断。(See longer response on Medium, “Do Algorithms Reveal Sexual Orientation or Just Expose our Stereotypes?”)

- 这个例子中的偏见有:Selection Bias + Experimenter’s Bias + Correlation Fallacy
- 但事实上,在自拍中,同性恋和异性恋之间的差异与打扮、表现和生活方式有关,也就是说,这是一种文化的差异,而不是面部结构的差异。甚至可以通过构造一颗简单的打扮特征的决策树来判断。(See longer response on Medium, “Do Algorithms Reveal Sexual Orientation or Just Expose our Stereotypes?”)
- …
总而言之,算法偏见十分常见。但如果AI做不到无偏见,我们又怎么能够相信他们的判断? 那么我们该怎样做,才能避免算法偏见?当我们在提及算法公平性的时候,我们在谈论什么?
Reference
[1] Jonathan Gordon and Benjamin Van Durme. 2013. Reporting bias and knowledge acquisition. In Proceedings of the 2013 workshop on Automated knowledge base construction (AKBC ‘13). DOI:https://doi.org/10.1145/2509558.2509563
[2] Smithsonian. Artificial Intelligence Is Now Used to Predict Crime. But Is It Biased? 2018
[3] ProPublica. Northpointe: Risk in Criminal Sentencing. 2016.
[4] Xiaolin Wu, Xi Zhang: Automated Inference on Criminality using Face Images. CoRR abs/1611.04135 (2016)
[5] Wang, Yilun, and Michal Kosinski. 2017. “Deep Neural Networks Are More Accurate Than Humans at Detecting Sexual Orientation from Facial Images.” PsyArXiv. September 7. doi:10.1037/pspa0000098.